系列文章
汇编语言程序设计(一)
寄存器
在学习汇编的过程中,我们经常需要操作寄存器,那么寄存器又是什么呢?它是用来干什么的?
它有什么分类?又该如何操作?…
你可能会有许多的问题,答案都会在本文中进行揭晓。
1 寄存器的概念
一个典型的CPU由运算器、控制器、寄存器等器件组成 ,这些器件靠内部总线相连,内部总线实现CPU,内部各个器件之间的联系,而CPU与外设(主板上的其他器件)之间的联系则由外部总线连接。
简单来说,在CPU中:
1):运算器进行信息处理;
2):寄存器进行信息存储;
3):控制器控制各种器件进行工作;
4):内部总线连接各种器件,在他们之间进行数据的传送;
下图为cpu组成:
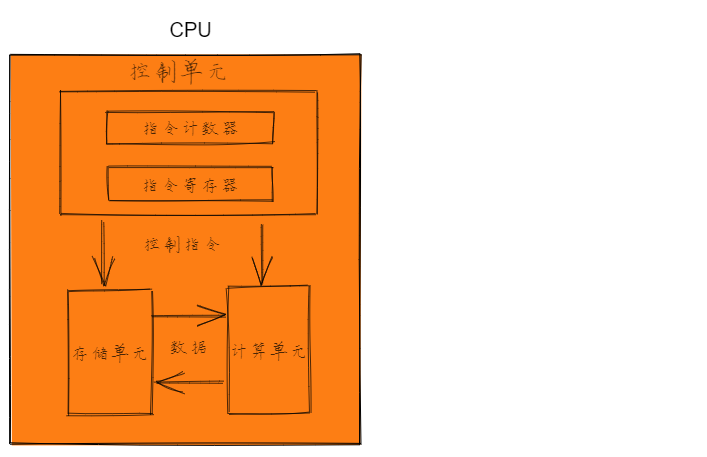
从上述描述中我们可以看出寄存器可以用来存储指令和数据。对于一个汇编程序员来说,CPU的主要部件是寄存器。寄存器是CPU中程序可以用指令读写的器件。程序员通过改变各种寄存器中内容来实现对CPU的控制。不同的CPU,寄存器的个数、结构是不同的。8086CPU由14个寄存器,每个寄存器有一个名称。这些寄存器是:AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW。这些寄存器有着不同的功能,在不同的场合扮演着不同的角色。后续的讲解中我们将逐渐接触到这些寄存器,这里我们就不一一介绍。
这里我们先介绍一些通用寄存器:AX、BX、CX、DX
8086CPU所有寄存器都是16位的,可以存放两个字节,上述4个寄存器通常用来存放一般性的数据,被称为通用寄存器。以AX为例,寄存器的逻辑结构如下图

一个16位寄存器可以存储一个16位的数据,例如如果AX中存储的是32这个数值,存放结果如下图所示:

而8086CPU为了兼容上一代CPU中的寄存器(上一代CPU中的寄存器位8位),上述这些寄存器又可以分为两个可独立使用的8位寄存器来用:AX可以分为AH、AL,同理,BX又可以分为BH、BL,CX可以分为CH、CL,DX可以分为DH、DL(H位high,L为low),以AX为例,它拆分成两个独立的8位寄存器表示如下:
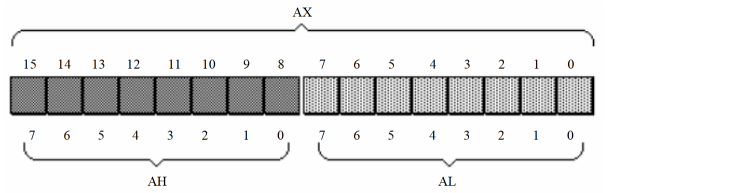
AX的低8bits构成了AL寄存器,高8bit构成了AH寄存器,AH和AL都是可以独立使用的寄存器。
2 字的存储
我们应该听过字节的概念,1字节等于8比特位,那么字和字节又有什么关联呢?1个字等于2个字节。
比特记为bit,字节记为Byte,字记为word,所以有如下关系:
1Byte = 8bits,1word = 2Bytes = 16bits
而8086CPU出于兼容性的考虑,一次性可以处理两种尺寸的数据:字节以及字数据
一个寄存器可以存储一个字数据,例如数据2000,其二进制数值为:0000 0111 1101 0000,储存格式如下:
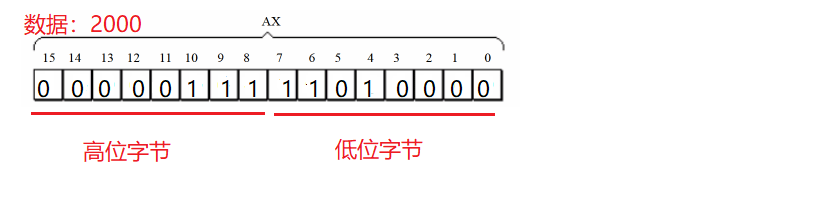
这样就是2000在寄存器中的存储格式(以AX为例),在AH中储存了它的高八位,AL存储了它的低八位。AH和AL中的数据可以看成一个整体是数值为2000,又可以看成是两个独立的数据,分别是7和208。上述是从寄存器出发,描述了一个16位数据在寄存器中的存储格式,而我们在使用汇编的过程中还会操作内存,那么在内存中一个字又可以用怎么样的格式体现呢?
我们要知道内存单元是字节单元也就是说一个字节单元对应一个内存单元,当我们要保存一个子数据时,我们应该用两个地址连续的内存单元来保存。数据的低字节存放在低地址单元中,高字节存放在高地址单元中,假设我们从0地址开始存放2000,情况如下:

我们用0、1两个内存单元存放数据2000(07D0H)。0、1两个单元用来储存一个字,这两个单元可以看成一个起始地址为0的字单元,对于这个字单元来说,0是低地址单元,1是高地址单元。07H被存放在高地址单元,而D0H被存放在低地址单元。同理,我们也可以把2,3看成一个字单元。
在这里有一个新的概念:字单元,用来描述一种用来存储字型数据的内存单元。
3 物理地址与段地址
CPU在访问内存单元之前,应该要给出内存单元的地址。所有的内存单元构成的存储的空间是一个一维的线性空间,每一个内存单元在这个空间中都有一个唯一的地址,我们称之为物理地址。
那么8086CPU又是如何形成这些物理地址的呢?
我们案例中的8086CPU是16位机,这种CPU具备如下特性:
1):一次最多可以处理16位的数据;
2):寄存器的最大宽度是16位;
3):寄存器和运算器之间的通路为16位;
也就是说,8086CPU内部一次性能处理的数据长度最大为16位。内存单元的地址在送上地址总线之前还需要经过寄存器进行处理,也就是说16位CPU,能一次性处理16位的地址。但是8086CPU的地址总线是20位,也就是说8086CPU可以传送20位地址,这与上述说法相悖,那这又是为什么呢?
8086CPU在内部有一个地址加法器可以将两个16位地址合成一个20位物理地址,示意图如下:
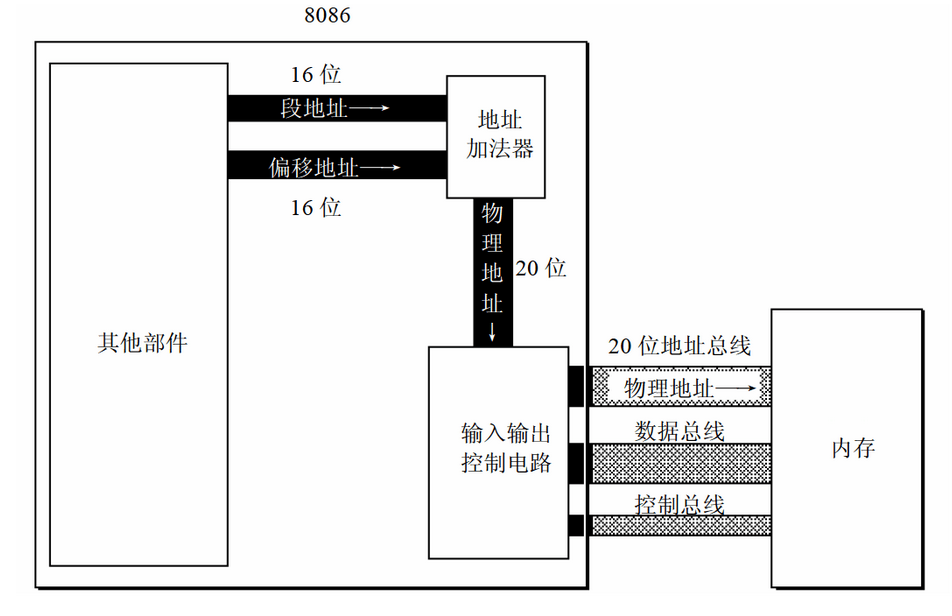
当CPU要操作内存时,内部有如下事件发生:
1):CPU中的相关部件提供了两个16位地址,一个称为段地址,一个称为偏移地址;
2):段地址和偏移地址经过内部总线送入地址加法器;
3):地址加法器将两个16位地址合成一个20位的物理地址;
4):地址加法器将20位的物理地址通过内部总线送入输入输出控制电路;
5):输入输出控制电路将20位地址送入地址总线
6):20位物理地址被地址总线送到存储器
地址加法器采用物理地址=段地址*16+偏移地址的方法来合成物理地址,这样一个16位机就可以访问20位地址,寻址能力也从64KB扩大成1MB。
例如CPU要访问地址为123C8H的内存单元,地址加法器的工作过程为:
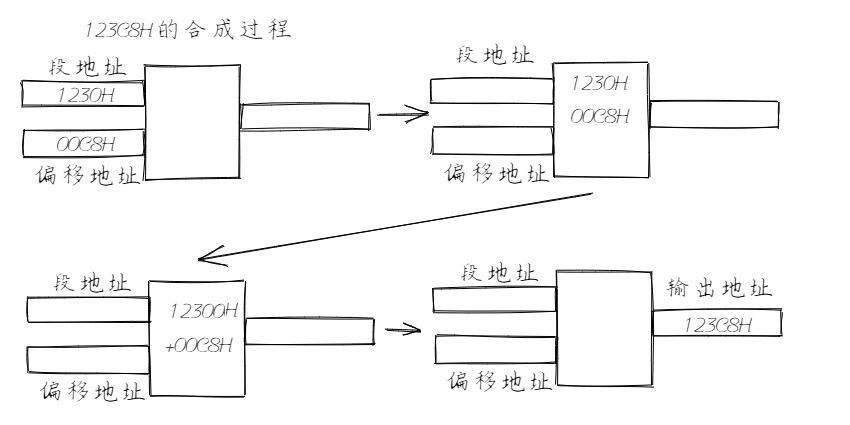
4 CS和IP
在讲CS和IP之前,我们需要了解一个概念:段。
上节我们讲到“段地址”,那么段又是什么呢?段和段地址有什么关系呢?在中文中我们可以很好的理解段的含义:表示某个范围/区间,也就是说“段地址”我们可以理解为一段地址,更规范的说法是一块地址连续且起始地址为16倍数的存储单元定义为一个段。也就是说我们可以将内存进行分段处理,当然我们不要误解为内存本身就是一段一段的,这是一个错误的认知。内存本身是连续的,只不过8086CPU采用“物理地址=段地址*16+偏移地址”来产生物理地址,我们可以通过分段的方式来管理内存。
假设目前有两个段:10000H ~ 1007FH(段地址为1000H)、10080H ~ 100FFH,段地址为(1008H),两个段大小均为80H,其内存中分布示意如下:
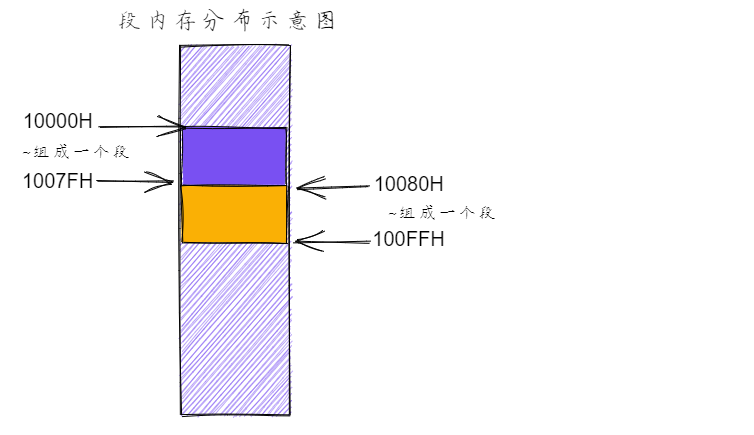
这样我们在编程时就可以根据需要将一块地址连续的存储单元看成一个段,通过“物理地址=段地址*16+偏移地址”来定位段中的内存。注意:段地址一定是16的倍数,且段的最大长度为64KB。
从上述描述中我们已经知道了什么是段了,在前面的讲述中我们说段地址是由CPU中的相关部件提供,那么这个相关部件是哪个呢?在众多的寄存器中的有4个**段寄存器:**CS,DS,SS,ES。当CPU要访问内存时,由他们提供段地址。这里我们看一下CS。
CS和IP是8086CPU中最关键的两个寄存器。它们指示CPU当前要读取的指令的地址。CS称之为代码段寄存器,IP为指令指针寄存器。
在8086CPU中,任意时刻设CS中的值为M,IP中的值为N,则CPU将从M*16+N地址单元中取出一条指令并执行。也就是说,当前执行的指令在哪由CS和IP来决定。可以表示为CS:IP。下图为CPU通过CS、IP寄存器进行指令操作:
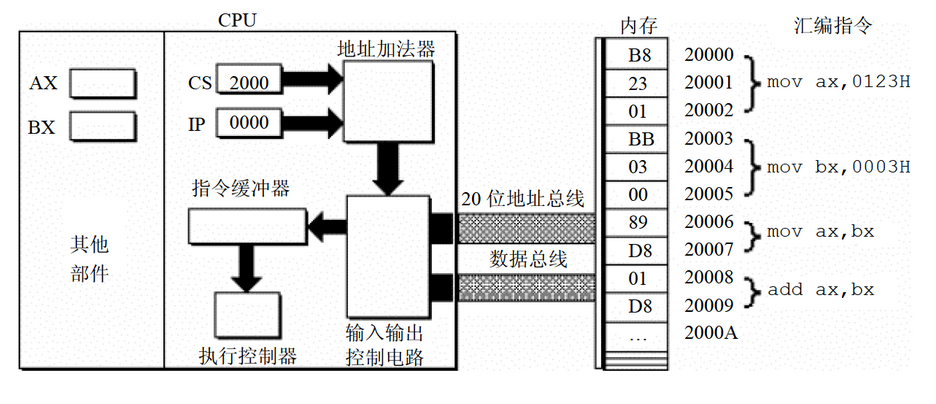
上图说明如下:
1):CS中内容为2000H,IP内容为0000H:说明物理地址为20000H
2):内存20000H~20009H内存单元中存放着可执行的机器码
3):内存20000H~20009H内存单元中存放的可执行的机器码对应的汇编指令如下:
地址:20000H~20002H 内容:B8 23 01 对应的汇编指令:mov ax,0123H
地址:20003H~20005H 内容:BB 03 00 对应的汇编指令:mov bx,0003H
地址:20006H~20007H 内容:89 D8 对应的汇编指令:mov ax,bx
地址:20008H~20009H 内容:01 D8 对应的汇编指令:add ax,bx
那么上述的状态下程序又是如何执行的呢?
1):CPU从CS:IP指向的存储单元中读取指令,读取的指令进入指令缓冲区;
2):IP=IP+所读取的指令的长度,从而指向下一条指令;
3):执行指令。重复1、2步。
注意:8086CPU在启动/复位启动之后,CS被设置为FFFFH,IP被设置为0000H,也就说,8086CPU在启动时执行的的第一条指令为FFFF0H指向单元中的指令。
5 DOS软件的安装及使用
关于DOS:磁盘操作系统(Disk Operating System),是早期个人计算机上的一类操作系统。从1981年MS-DOS1.0直到1995年MS-DOS 6.22的15年间,DOS作为微软公司在个人计算机上使用的一个操作系统载体,推出了多个版本。DOS在IBM PC 兼容机市场中占有举足轻重的地位。可以直接操纵管理硬盘的文件,以DOS的形式运行。
DOS家族包括MS-DOS、PC-DOS、DR-DOS、FreeDOS、NovellDOS、PTS-DOS、ROM-DOS、JM-OS等,其中以MS-DOS最为著名,最自由开放的则是Free-DOS。虽然这些系统常被简称为"DOS",但没有任何一个系统单纯以"DOS"命名。
DOSBOX软件下载:可以自己去网上下载
MASM软件包下载:可以自己去网上下载
关于DOS的安装:一路向下即可(对于安装位置选择自行浏览)
MASM安装:不需要安装直接解压即可(解压在你设置的虚拟C盘)
关于DOS的指令:(不做深入)
1. dir
查看当前目录下文件和文件夹
2. cd
进入特定目录
cd code 进入当前目录下的code目录
cd\ 切换到根目录
cd.. 切换到上一级目录
3.md
建立特定文件夹
md code 在当前目录下建立一个名字叫code的目录
4.rd
删除特定文件夹
rd code 删除当前目录下的code文件夹
5.cls
清除屏幕。清除屏幕上所有的显示内容。只留下当前的命令行。
6.exit
推出当前命令解释程序并返回到系统
//其他指令大家可以自己了解,这里不做过多深入
程序的编译过程:
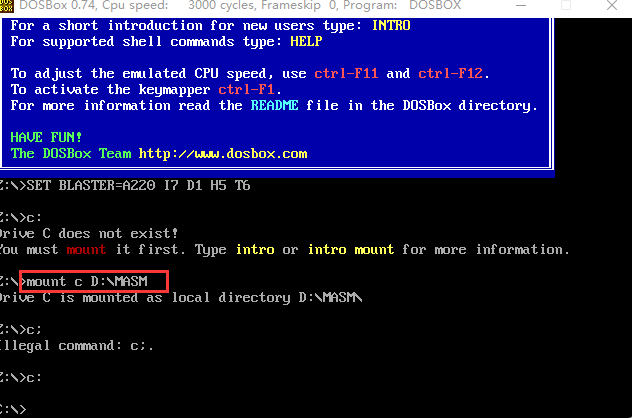
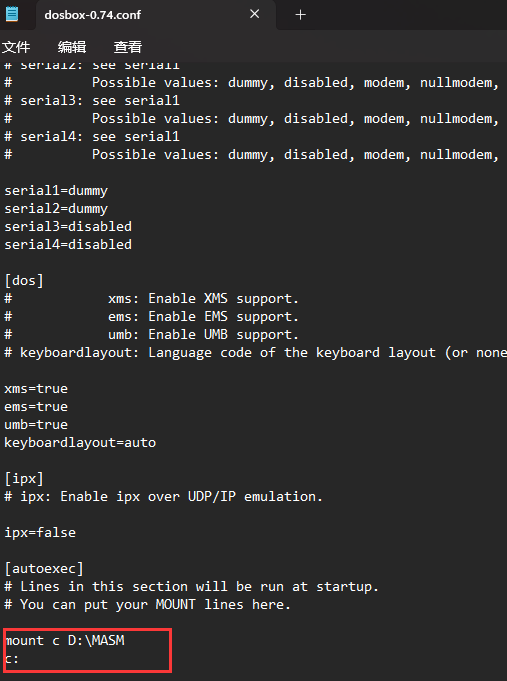
1.设置虚拟盘
mount c D:\MASM //将D盘目录下的MASM的作为虚拟盘C盘
2.进入到设置到的C盘
c:
3.在D:\MASM文件夹下新建一个1.asm
直接在windows中创建即可
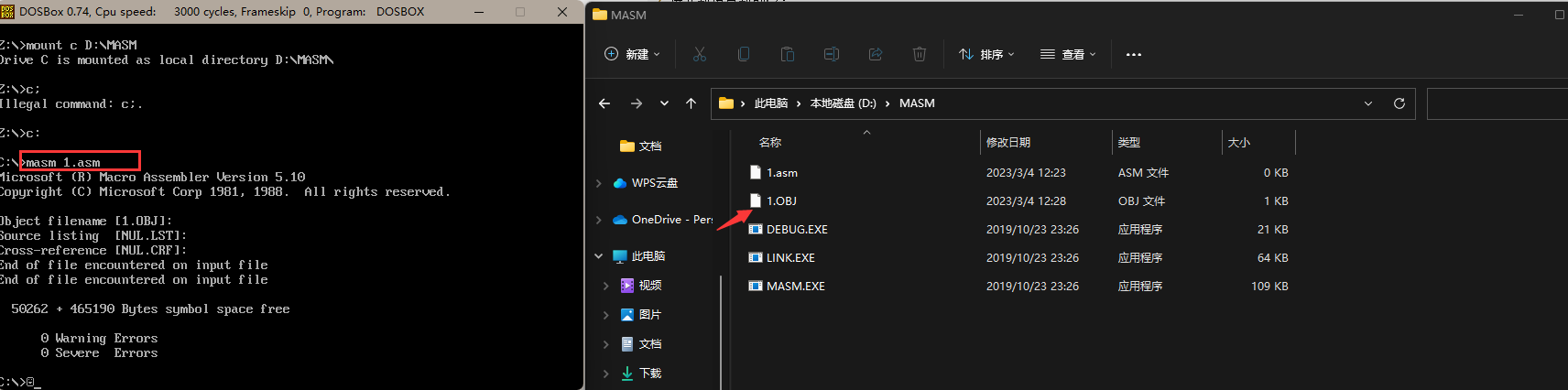
4.编译源文件
masm 1.asm //---》这里会产生一个中间文件 1.obj
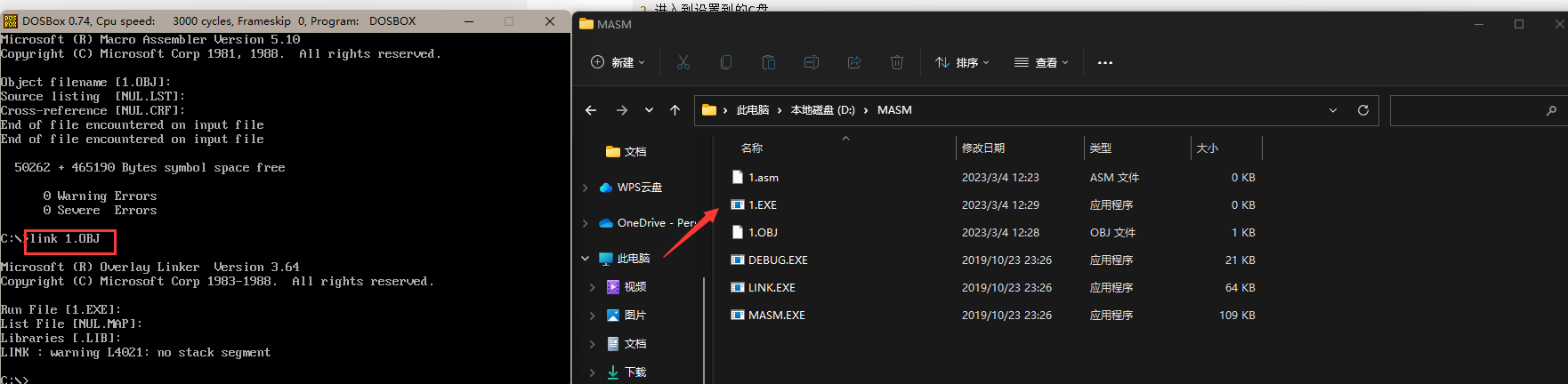
5.链接
link 1.obj //---》这里会产生一个目标文件 1.exe
6.1.exe即为可执行程序,可以直接执行了(输入名字即可)
上述1-2步每次开启DOS时都要执行,这样比较麻烦,做如下处理就不需要开机时输入了:
打开DOSBOX的安装文件夹,找到DOSBox 0.74 Options,打开,在其末尾添加这两行
mount c D:\MASM
c:
设置DOS窗口大小:
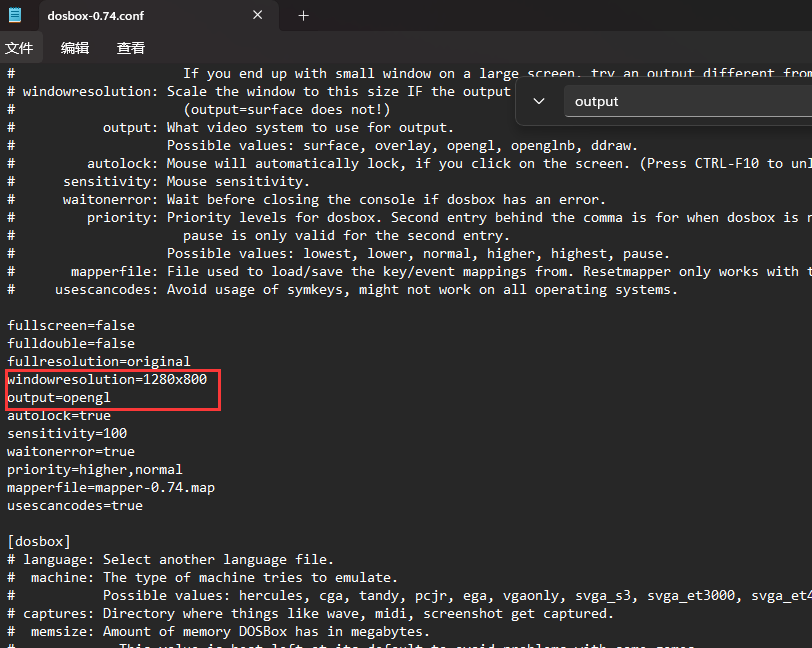
打开DOSBOX的安装文件夹,找到DOSBox 0.74 Options,打开,找到windowresolution以及output修改成如下
windowresolution=1280x800
output=opengl
程序的debug过程:
上述操作生成一个可执行程序之后,比如说1.exe
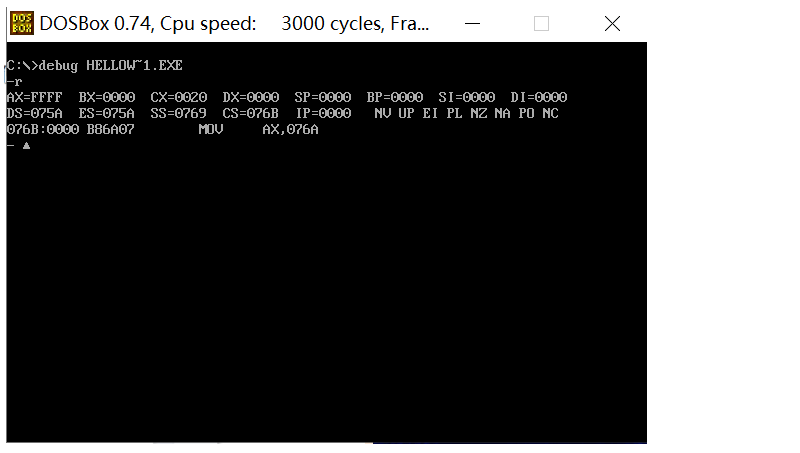
在DOS命令行输入:debug 1.exe
R命令查看/修改CPU中寄存器的内容
输入:r ax 回车
会出来一个:在后面输入你想要改变的数据就可以改变ax中的内容,其它寄存器同理
D命令查看内存中的内容
d段地址:偏移地址 回车可以查看该物理地址制定的内存中的内容
如:d1000:0000
E命令改写内存中的内容
e 段地址:偏移地址 要修改的内容
如:e 1000:0000 0 1 2 3 4 5 6 7
U命令将内存中的机器指令翻译成汇编指令
简单理解为查看源码
T命令执行一条机器指令
单步执行程序
A命令以汇编指令的格式在内存中写入一条机器指令
...
quit 退出debug
6 段的分类
前面讲过,对于8086PC机,再编程时可以根据需要将一组内存单元定义为一个段。我们可以将长度为N(N<=64KB)的一组代码,存在一组地址连续、起始地址为16的倍数的内存单元中,我们可以认为,这段内存是用来存储代码的,从而定义了一个代码段。比如:
mov ax,0000 ;(B8 00 00)
add ax,0123H ;(05 23 01)
mov bx,ax ;(8B D8)
jmp bx ;(FF E3)
上述代码长度为10个字节(括号里面的为每条指令对应的机器码)的指令,我们将它存放在 123B0H-123B9H 的一组内存单元中,我们就可以认为 123B0H-123B9H这段内存是用来存放代码的,是一个代码段,段地址为123BH,长度为10个字节。
虽然我们可以将上述代码设置在一个代码段内,但是这仅仅我们编程时的一种安排,CPU并不会因为这种安排,就自动的将我们定义的代码段中的指令当做指令来执行。CPU只认被CS:IP指向的内存单元中的内容为指令。所以,要让CPU执行我们设置为代码段中指令,我们需要改变CS:IP指向的内容,换而言之,需要将CS:IP指向123B0这个单元。也就是说需要设置CS=123BH,IP=0000H。在这里大家只要知道有代码段这个概念即可,不需要做太多过于深入的探讨。
我们可以假想这组数据可以存储在某块内存内,我们知道这块内存的地址,那么我们在使用时就可以通过内存地址找到这些数据了。我们参考上述代码段的概念,我们可以设置一个数据段,用来存储这组数据。同样的,对于数据段来说,这仍然是我们编程时的一种安排,再具体操作的时候,我们需要将DS寄存器存放数据段的段地址,当我们在使用数据的时候只需要给出偏移地址就可以了,例如如下程序:
(我们假设这个数据段的段地址为123B0H)
mov ax,123BH
mov ds,ax ;将123BH送入ds中,作为数据段的段地址 (这里不能直接 mov ds,123BH)
mov al,[0] ;这句话的含义是将123B0:0000H单元中的内容存入al中
在这里我们就可以好好的认识一下这几个段寄存器了:CS,DS,SS,ES
代码段寄存器(code segment):CS
存放当前正在运行的程序代码所在段的段基址,表示当前使用的指令代码可以从该段寄存器指定的存储器段中取得,相应的偏移地址则由**IP(指令指针寄存器)**提供;
数据段寄存器(data segment):DS
指出当前程序使用的数据所存放段的最低地址,即存放数据段的段地址;
栈段寄存器(stack segment):SS
指出当前堆栈的底部地址,即存放堆栈段的段基址。SS:SP指向栈顶单元。
附加段数据寄存器(extra segment):ES
指出当前程序使用附加数据段的段基址,该段是串操作指令中目的串所在的段。
前面我们已经讲解了数据段和代码段,后续的附加段数据寄存器在讲解串操作指令时再进行讲解。接下来我们重点讲一下栈段寄存器SS。
首先我们先研究一下栈:栈是一种具有特殊的访问方式的存储空间。特殊性在于最后进入这个空间的数据最先出去。我们用下面的图示和描述来向大家讲解这个概念:
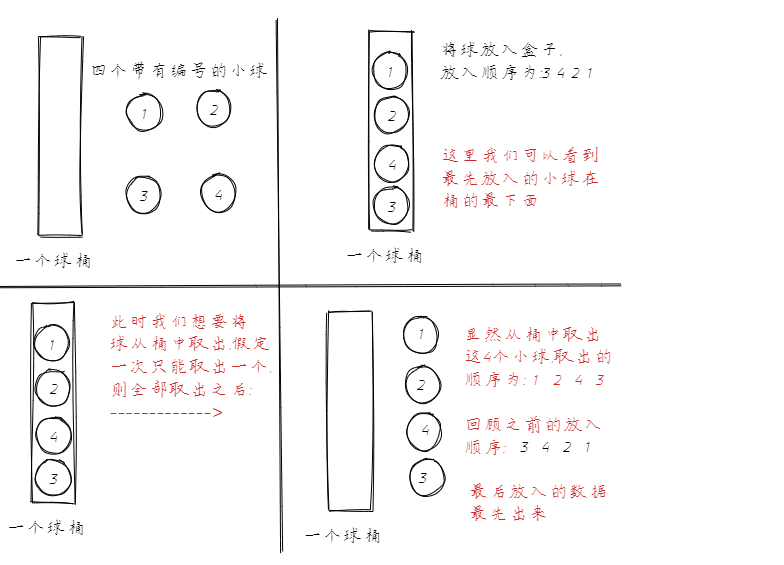
从图中的可以看出,小球的放入顺序和取出顺序刚好相反**(球桶口在上方,底部不能进行球的放入)**
当然从程序化的角度来看,我们要取出球(所在内存),应该有一个标记,这个标记一直指示着这个球桶最上方的球的位置。我们将上述的球桶看成是一个栈,将元素(球)放入栈(桶)的操作我们称之为入栈,从栈中取出元素的操作我们称之为出栈。入栈就是将一个新的元素放到栈顶,出栈就是从栈顶取出一个元素。栈顶的元素总是最后入栈,需要出栈时,栈顶元素又最先被取出。栈的这种操作规则被称为:
LIFO(Last In First Out,后进先出)。
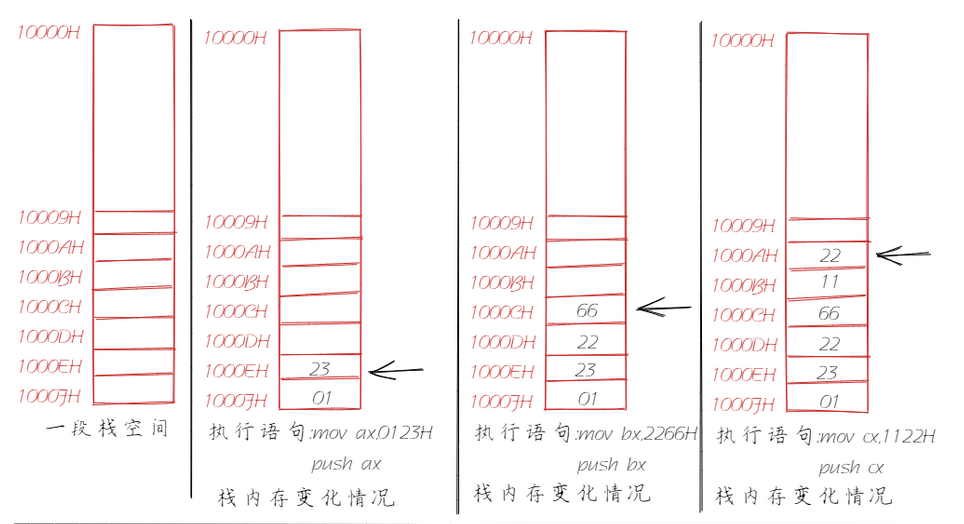
8086CPU同样支持栈,相应的提供了两个指令用于出栈以及入栈:PUSH(入栈)和POP(出栈)。这样,我们在编程时就可以将一段内存当成栈来使用,像这样的一段内存我们就称之为栈段。我们假定将10000H~1000FH这段内存当作栈来使用,通过分析下面的代码和图示来看一下栈的工作过程。8086CPU的入栈和出栈操作都是以字为单位。(高地址,存放高8bit,低地址,存放低8bit)
mov ax,0123H
push ax
mov bx,2266H
push bx
mov cx,1122H
push cx
pop ax
pop bx
pop cx
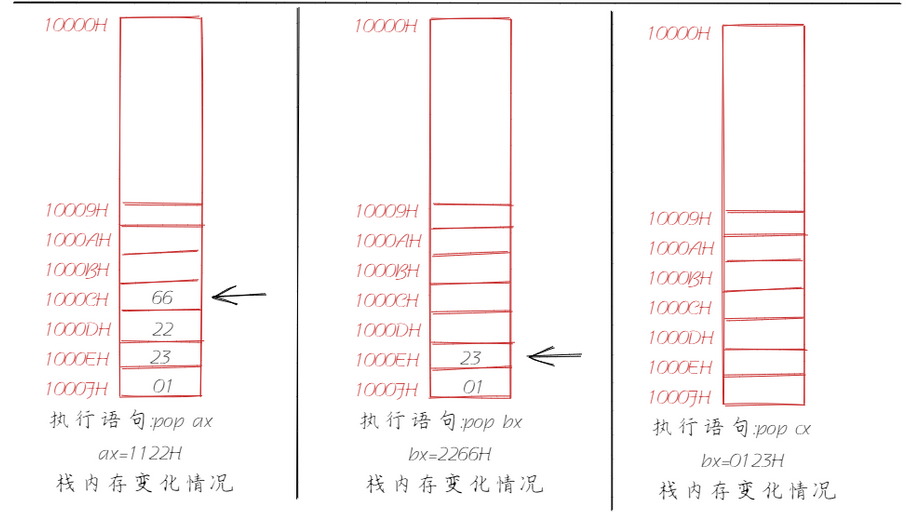
上述的图示对应着代码分析就是出栈入栈过程,但是CPU怎么知道你这个段在哪里呢?它又怎么知道这段空间要被当成栈来使用呢?当CPU需要将数据进行入栈操作,我们知道入栈是将一个元素添加进入栈顶,那么CPU又怎么知道栈顶在哪呢?
结合前面CS、IP的讲解,我们应该不难推出CPU有相应的寄存器标记这个栈空间,同理栈顶也应该有个寄存器来标记。这就是我们要讲的SS(栈段寄存器)和SP(栈顶指针寄存器),栈段地址存放在SS寄存器中,偏移地址存放在SP寄存器中。任意时刻,SS:SP指向栈顶元素。push指令和pop指令执行时,CPU从SS和SP中得到栈顶的地址。现在我们又可以对上述的示例有一个更加深入的理解。
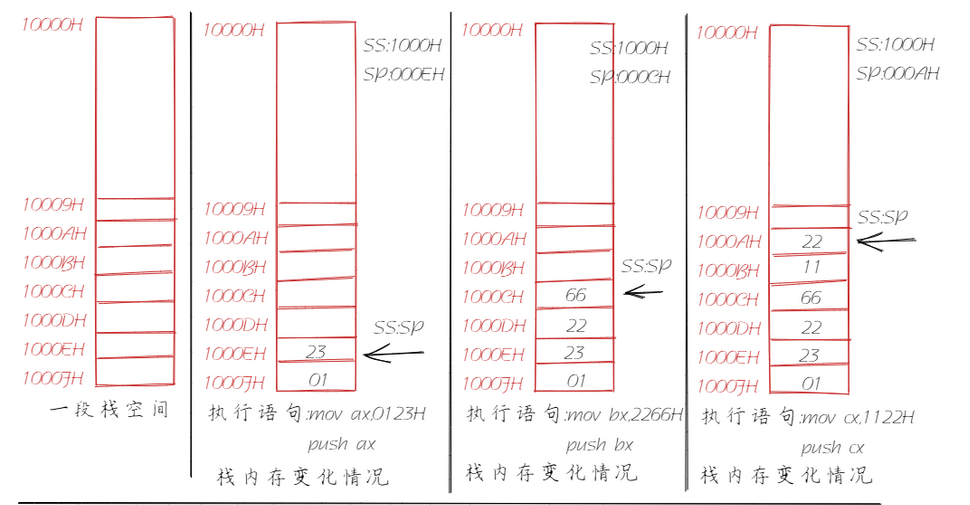
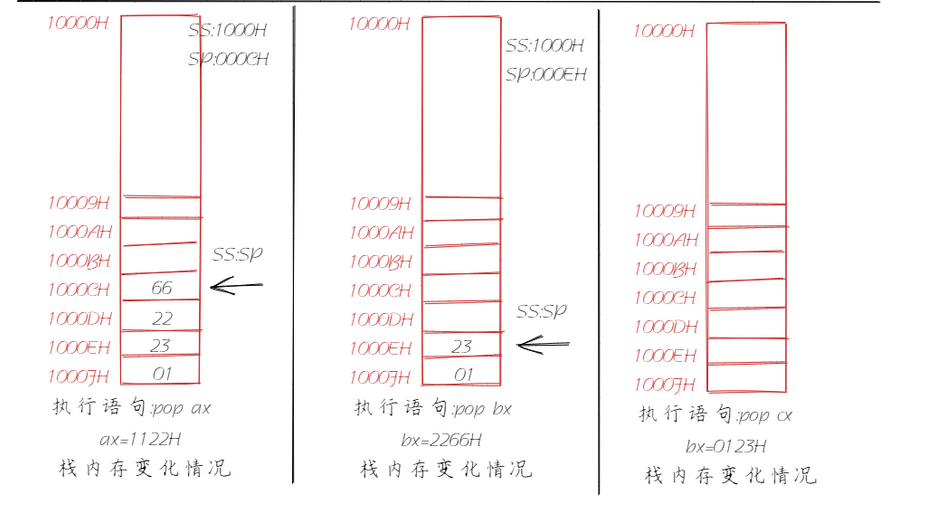
这里我们需要注意,当栈为空时,SS=1000H,那么SP又该指向谁呢?SP=0010H。
我们大致已经明白了栈以及栈空间了,同代码段和数据段的定义类似,我们在编程时可以根据需要,将一组内存单元定义为一个段当成一个栈段。在使用时,我们需要将SS:SP指向我们定义的栈段,利用POP和PUSH指令对栈空间进行操作。


![[ant-design-vue] tree 组件功能使用](https://img-blog.csdnimg.cn/d9776c234f844e42ad0792fca7647eaf.png)